Introduction to Development
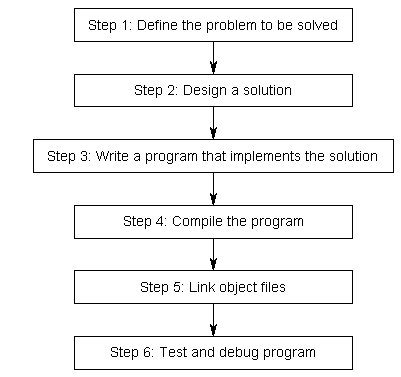
Before we can write and execute our first program, we need to understand in more detail how programs get developed. Here is a graphic outlining a simplistic approach:
Step 1: Define the problem that you would like to solve.
This is the “what” step, where you figure out what you are going to solve. Coming up with the initial idea for what you would like to program can be the easiest step, or the hardest. But conceptually, it is the simplest. All you need is a an idea that can be well defined, and you’re ready for the next step.
Step 2: Determine how you are going to solve the problem.
This is the “how” step, where you determine how you are going to solve the problem you came up with in step 1. It is also the step that is most neglected in software development. The crux of the issue is that there are many ways to solve a problem — however, some of these solutions are good and some of them are bad. Too often, a programmer will get an idea, sit down, and immediately start coding a solution. This almost always generates a solution that falls into the bad category.
Typically, good solutions have the following characteristics:
* They are straightforward
* They are well documented
* They can be easily extended (to add new features that were not originally anticipated)
* They are modularized
The problem is largely with the third and fourth bullets — while it’s possible to generate programs that are straightforward and well documented without using a lot of forethought, designing software that is extensible and sufficiently modularized can be a much tougher challenge.
As far as extensibility goes, when you sit down and start coding right away, you’re typically thinking “I want to do _this_”, and you never consider that tomorrow you might want to do _that_. Studies have shown that only 20% of a programmers time is actually spent writing the initial program. The other 80% is spent debugging (fixing errors) or maintaining (adding features to) a program. Consequently, it’s worth your time to spend a little extra time up front before you start coding thinking about the best way to tackle a problem, and how you might plan for the future, in order to save yourself a lot of time and trouble down the road.
Modularization helps keep code understandable and reusable. Code that is not properly modularized is much harder to debug and maintain, and also harder to extend later. We will talk more about modularization in the future.
Step 3: Write the program
In order the write the program, we need two things: First we need knowledge of a programming language — that’s what these tutorials are for! Second, we need an editor. It’s possible to write a program using any editor you want, be it Window’s notepad or Linux’s gedit. However, we strongly urge you to use an editor that is designed for coding.
A typical editor designed for coding has a few features that make programming much easier, including:
1) Line numbering. Line numbering is useful when the compiler gives us an error. A typical compiler error will state “error, line 64″. Without an editor that shows line numbers, finding line 64 can be a real hassle.
2) Syntax highlighting and coloring. Syntax highlighting and coloring changes the color of various parts of your program to make it easier to see the overall structure of your program.
3) An unambiguous font. Non-programming fonts often make it hard to distinguish between the number 0 and the letter O, or between the number 1, the letter l (lower case L), and the letter I (upper case i). A good programming font will differentiate these symbols in order to ensure one isn’t accidentally used in place of the other.
Your C++ programs should be called name.cpp, where name is replaced with the name of your program. The .cpp extension tells the compiler (and you) that this is a C++ source code file that contains C++ instructions. Note that some people use the extension .cc instead of .cpp, but we recommend you use .cpp.
Also note that many complex C++ programs have multiple .cpp files. Although most of the programs you will be creating initially will only have a single .cpp file, it is possible to write single programs that have tens if not hundreds of individual .cpp files.
Step 4: Compiling
In order to compile a program, we need a compiler. The job of the compiler is twofold:
1) To check your program and make sure it follows the syntactical rules of the C++ language:
2) To take your source code as input and produce a machine language object file as output. Object files are typically named name.o or name.obj, where name is the same name as the .cpp file it was produced from. If your program had 5 .cpp files, the compiler would generate 5 object files.
For illustrative purposes only, most Linux and Mac OS X systems come with a C++ compiler called g++. To use g++ to compile a file from the command line, we would do this:
"g++" -c file1.cpp file2.cpp file3.cpp *
This would create file1.o, file2.o, and file3.o. The -c means “compile only”, which tells g++ to just produce .o files.
Other compilers are available for Linux, Windows, and just about every other system. We will discuss installing a compiler in the next section, so there is no need to do so now.
For complex projects, some development environments use a makefile, which is a file that tells the compiler which files to compile. Makefiles are an advanced topic, and entire books have been written about them. We will not discuss them here.
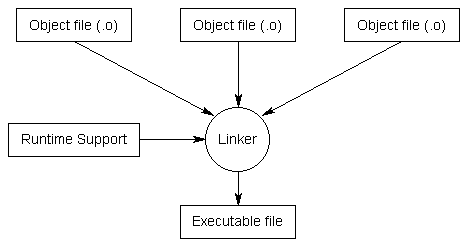
Step 5: Linking
Linking is the process of taking all the object files for a program and combining them into a single executable.
In addition to the object files for a program, the linker includes files from the runtime support library. The C++ language itself is fairly small and simple. However, it comes with a large library of optional components that may be utilized by your program, and these components live in the runtime support library. For example, if you wanted to output something to the screen, your program would include a special command to tell the compiler that you wanted to use the I/O (input/output) routines from the runtime support library.
Once the linker is finished linking all the object files (assuming all goes well), you will have an executable file.
Again, for illustrative purposes, to link the .o files we created above on a Linux or OS X machine, we can again use g++:
g++ -o prog file1.o file2.o file3.o
The -o tells g++ that we want an executable file named “prog” that is built from file1.o, file2.o, and file3.o
The compile and link steps can be combined together if desired:
g++ -o prog file1.cpp file2.cpp file3.cpp
Which will combine the compile and link steps together and directly produce an executable file named “prog”.
Step 6: Testing and Debugging
This is the fun part (hopefully)! You are able to run your executable and see whether it produces the output you were expecting. If not, then it’s time for some debugging. We will discuss debugging in more detail soon.
Note that steps 3, 4, 5, and 6 all involve software. While you can use separate programs for each of these functions, a software package known as an integrated development environment (IDE) bundles and integrates all of these features together. With a typical IDE, you get a code editor that does line numbering and syntax highlighting. The IDE will automatically generate the parameters necessary to compile and link your program into an executable, even if it includes multiple files. And when you need to debug your program, you can use the integrated debugger. Furthermore, IDE’s typically bundle a number of other helpful editing features, such as integrated help, name completion, a class hierarchy browser, and sometimes a version control system.
We will talk more about installing and using IDEs in the next section.